期待大神的进一步优化
是的 大神就是这样
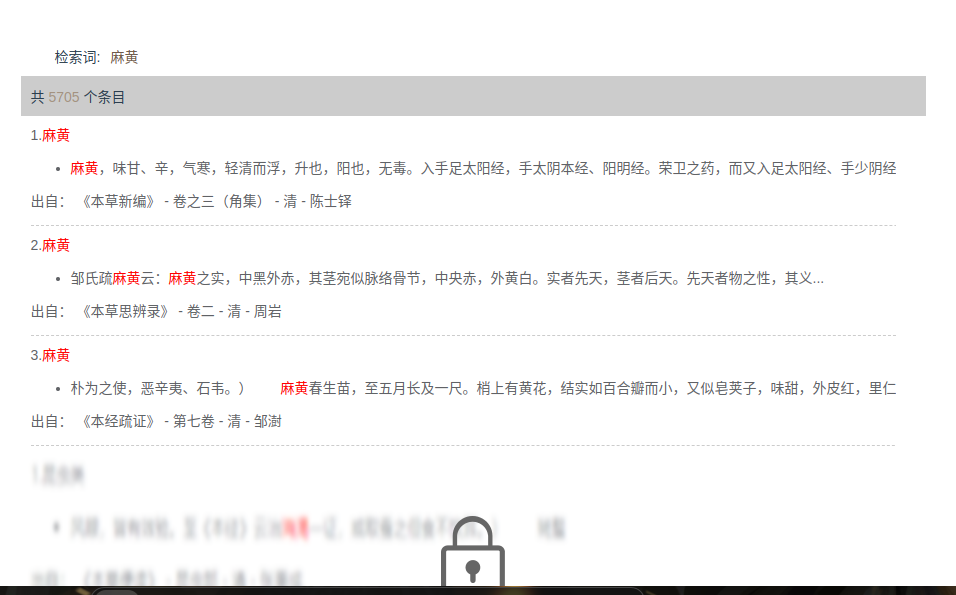
分条目
非常直观方便
OK,我知道了,感谢您的建议!
大神
衷心感谢呀
治学一道受益匪浅啊
不客气,我会一点一点进行优化的,最近在研发新的校对系统,网站这边的优化就放缓一些了
1 个赞
对于中医之钻研
举个例子
饮之概念,有
留饮
支饮
伏饮
悬饮
溢饮
癖饮
之种种区别
如无相关文献全文检索的
分列条文
很难有精确程度的思考,这是医学循证的要求。
吾兄之努力,小弟感佩万千
怫鬱
《病源》七疝候,七疝者,厥疝,症疝,寒疝,氣疝,盤疝,胕疝,狼疝也
这些概念要吃透
没有原文原典的条文
深入细致的钻研体会,那万万不行
所以辛苦大神了
感谢大神!功德无量!惠及学林!希望里面的文献比如明清小说之类的越来越多!
又又更新了!
1、全新的单人/团队模式校对平台,新模式、新界面、新功能。
2、全新的古籍识别OCR服务,OCR识别流程全量优化,识别能力大幅提升,修复简繁错乱问题,优化语句检测错误问题,优化语序排序问题。
欢迎体验:
OCR:https://kandianguji.com/ocr
校对平台:登录
1 个赞
2 个赞
用一段時間了,發現的問題有:
篆書識字效果不好
標點遺失(橫排優過豎排,豎排多會識別成文字)
橫排掃描經常錯位
感謝無私分享
嘉惠學林,功德無量。
感觉古籍刻本的OCR要实用,首先要过图像预处理这一关。
字节的项目选择的是《四部丛刊》
因为有质量较高的扫描图片,跳过了图像预处理问题。
但网络上哈佛燕京、日本内阁文库等大型开源的古籍刻本,扫描质量千差万别。

这样的扫描图片让商业AI引擎来OCR恐怕识别率也高不到哪里。
所以,是不是不要继续简单套用现成的算法架构,而是换个思路?比如先单字检测—再逐字OCR替换为文本—再组合成整页—运用特定外部语料库再次上下文检查,筛选置信度低的人工确认—Human Feedback用于下次单字检测OCR……