更新了?哪个是新样子?看了网盘,好像没有危机词典的更新。
弄错了,百科10月20号的上传了。字典还没有,因为10月20的数据只有1/20不到。
@meandmyhomies I tried using ijson librabry to stream the file enwiktionary_namespace_0_1.ndjson as follows:
from bs4 import BeautifulSoup
import ijson
folder_dir = "C:\\Users\\Akira\\Documents\\enwiktionary_namespace_0_1.ndjson"
# Open the JSON file
with open(folder_dir, 'r') as file:
# Parse the JSON objects one by one
parser = ijson.items(file, 'item', multiple_values=True)
n = 0
# Iterate over the JSON objects
for item in parser:
# Process each JSON object as needed
print('Hello Python!')
n = n + 1
if n > 10:
break
However, python returns nothing, i.e., there is no Hello Python!. Could you help me with this issue?
try this:
with open(ndjsonfilename, 'r',encoding='utf-8') as f, open(mdxfilename, 'w',encoding='utf-8') as g:
for line in f:
line = line.strip()
oJson = json.loads(line)
hwd = '|'.join([oJson["name"],str(oJson["identifier"]),oJson["url"]])
g.write(hwd+'\n')
data = ''.join([x.strip() for x in oJson["article_body"]['html'].split('\n')])
g.write(data)
del oJson["article_body"]
g.write('\n</>\n')
1 个赞
My laptop takes only 21.3s to run your code. I think the code is sequential (i.e., it processes line by line) and thus I’m surprised by this speed. May I ask how long it takes your laptop to run?
You have a very speedy laptop. It takes mine around at least 30 seconds to process. I would expect the CPU is not the bottleneck (single threaded here), but your timing is within expectation.
My laptop has only 32GB RAM. The good speed I obtain may be due to the high-speed RAM.
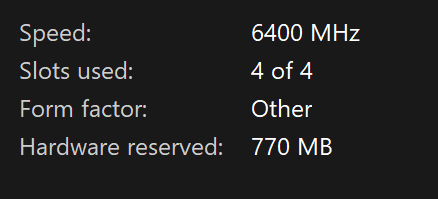
How long does it take your PC to process the whole English Wiktionary? Above conversion (from ndjson to txt) is very fast. So I guess the HTML processing (by bs4) may be the gist… I’m very interested in optimizing the conversion.
This step takes almost no time relatively. Total don’t exceed half an hour on 700GB of json data. The subsequent processing takes extremely long. Often 20-30 hours every 300GB of converted data.
1 个赞
If you don’t mind, please share with me the function you created to process the HTML. I very want to optimize it.
It is splashed across several files and cannot even be run without a lot of tweaking/docs and refactoring. The thing is clearly limited by the single threaded database queries. Fortunately the query does not have a memory limit. So unless I change my DB into an industrial strength one such as Oracle or db2 or SQL server, there is no way to make it go faster (my SSD is probably the next bottleneck).
1 个赞
For example, adding index after insert took 3317.02 seconds on 1/3 of the data in English wikipedia.
That step I see my SSD going at sustained 500MB-1TB per second for much of the time. Cannot speed this up much IMO.
Basically I am condensiing 700GB of json data into 45GB of mdx. I found the original json dump file contains 500K or so 【correction: 2 Million) duplicate records which takes up a lot of space too.
Could you explain more about ‘‘single threaded database queries’’. I thought we can do multiprocessing.
On the othe hand, I have recently found the package pandas_streaming which streams data. My code is
import pandas as pd
from bs4 import BeautifulSoup
from pandas_streaming.df import StreamingDataFrame
from multiprocessing import dummy
thread = 30
P = dummy.Pool(processes = thread)
file_dir = "C:\\Users\\Akira\\Documents\\enwiktionary_1.ndjson"
sdf = StreamingDataFrame.read_json(file_dir, lines=True, chunksize = 10000, encoding='utf-8')
for df in sdf:
res = P.map(process_html, df)
In above code, we only keep one chunk at a time to process. In this way, we will not run out of memory.
Processing HTML sequentially or in parallel does not consume too much CPU or memory if done in chunks. It’s when you do a global dedupe, and anything involving all the data at the same time which takes forever. If I did nothing global, then the 700GB json can be turned into mdx in 3-4 hours.
1 个赞
Voila Your explanation makes a lot of sense. I have never done any operation involved all the data. Could you mention some such global operations so that I can think of it?
This is for a smaller mdx which has around 100GB data, I found 489K duplicate records in the original data (german wikipedia). Try running in single thread in a database.

You meant it is not possible to find duplicate entries with multi-processing?
Not in ways which are faster than the database. A database is built for such tasks without blowing up the memory or disk.
May I ask what ‘‘duplicate tab’’ actualy means? Are they two similar entries/lines/htmls in such a ndjson file as enwiktionary_namespace_0_1.ndjson?
I was shocked at how many records are identical to each other. Half a million is a lot, almost more than the OED, the largest dictionary on earth. I dedupe across all json files, sometimes there are 350 of then in one mdx.