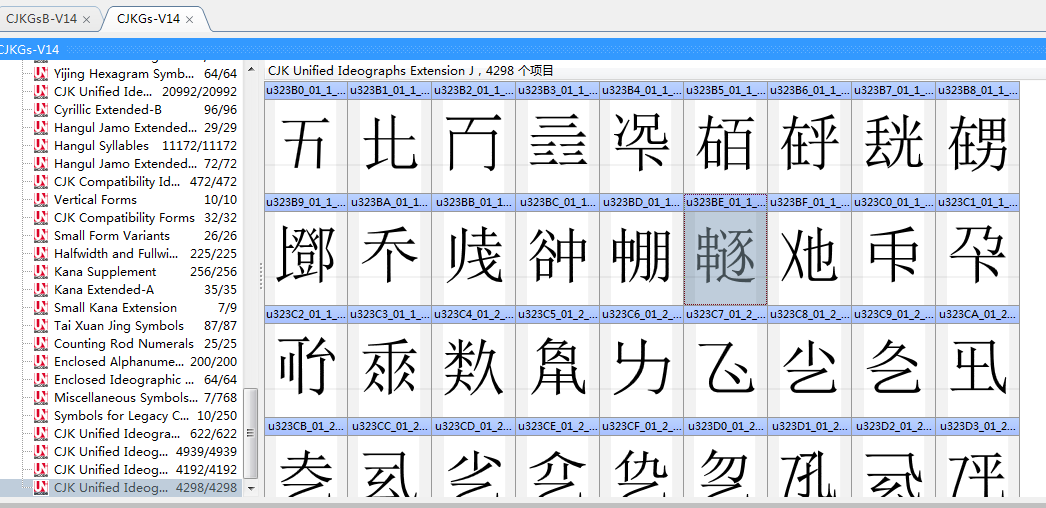
汉字辅助字典还是更专业,我只是从官方txt和pdf中提取字头,官方数据和字形图片,分平面引用字体显示生僻字,码点或字头查询,
辅助字典能做到提取15.1中300多个部首和全部的字头,和更实用的数据,包括笔画和文字演化,用60多种字体文件,展示每个字在不同语言和地区中的字形,还有悬浮放大的效果,码点或字头查询
更实用,更值得模仿学习
Unicode16和15.1中的字头一样,没有新增,等Unicode17出来了再跟进
感谢楼主做的词典,很好用。哪位大佬能再补个汉字辅助字典链接吗,感谢
1 个赞

这是我第一部作品,那时我还很年轻, ![]() ,我在等“文津字体”的Unicode17版本
,我在等“文津字体”的Unicode17版本

Unicode17的正式版相比之前的测试版,有无新增汉字?没有的话,直接字体换全宋体,css一改,mdd都不用新切图了
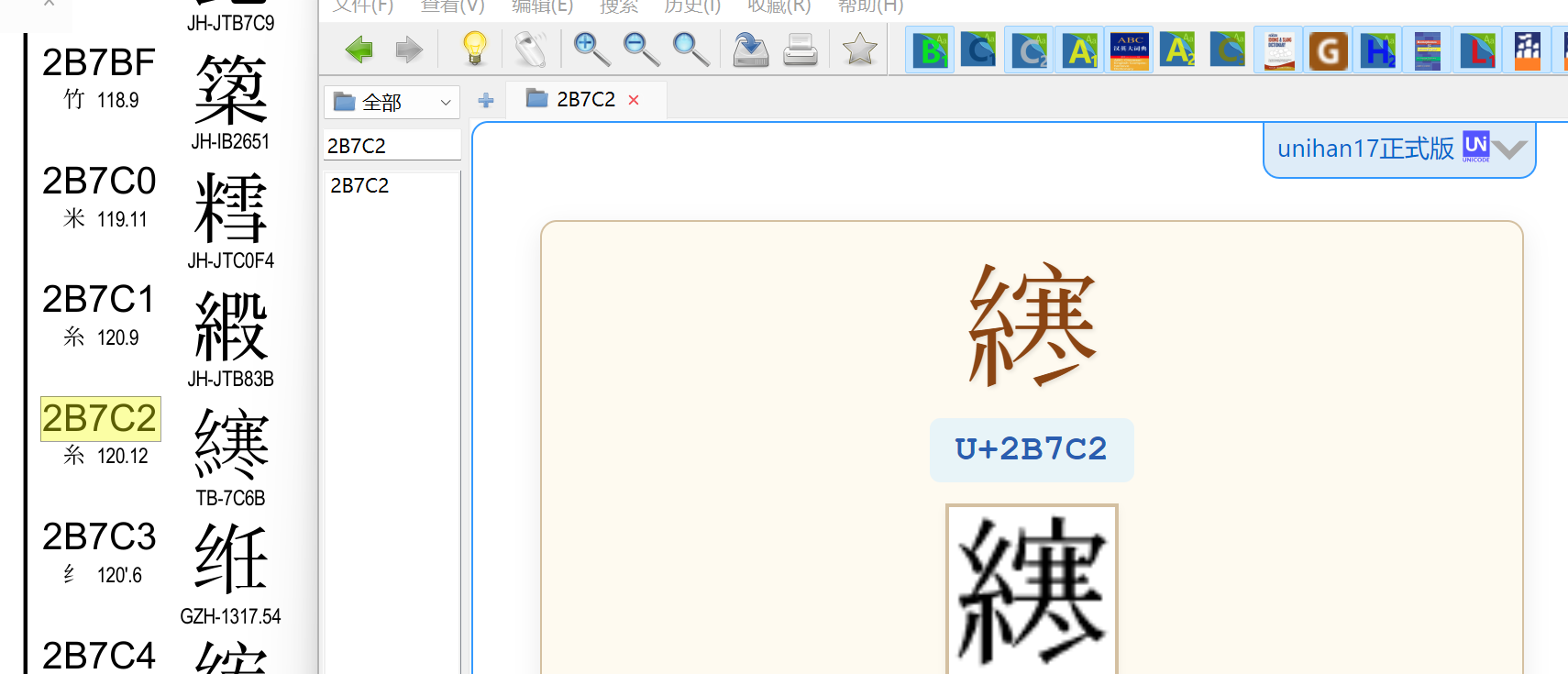
搞定了,显示部首,变体跳转显示汉字
2025-08-20 12:55 CodeCharts.pdf
pdf这边倒是有更新,不好排查是不是有改动
已使用,感谢更新
正式版文档的unihan的数据,还是2025-07-25的
pdf字形的话,没仔细看,看下了部分是有更新的
Unicode 17.0 Versioned Charts Index
如 𫟂
图片和字体还需要更新

感谢反馈,我看字数和预览版的一样,偷懒没有重新切pdf,到时候把17新增或者字形有变动的重新切一下,
我在想有没有方便快捷的做字体的方案,自己做字体,最好能照搬stable diffusion那样跑图,把已有的字体(2w字)做成lora,然后对照102998字的pdf跑一遍,自己做一个Unicode17字库
1 个赞
https://www.zhihu.com/question/640182358
这个页面下面的回答
项目源址
不过根据评论跑出的字体可能会比较粗糙,要美观的可能还是要逐个修
1 个赞
CUDA pytorch都是老熟人啊
和设想的一样,一个大模型,一个风格化的lora,然后炼丹抽奖,
估计以后会出现字体网站civitai ![]()
霞鹜臻楷(基于「霞鹜文楷」加粗衍生的开源中文字体)好像就用ai补字


文津宋体更新了

刚下载,我的好好哥哥 ![]()
字体和图片更新了,css也更新了,但是电脑端欧路正常,手机上面欧路和tango字体显示X,我不明白(奉化口音)