You meant that in this dump each entry may have many revisions each of which has a unique identifier?
So there is no way to tell if two lines in the ndjson file are indeed revisions of the same entry?
You meant that in this dump each entry may have many revisions each of which has a unique identifier?
So there is no way to tell if two lines in the ndjson file are indeed revisions of the same entry?
Yes, I never pay attn to the identifier field. They are meaningless for the purpose of detecting identical visible (human readable) contents, which is what matters.
In other words, most of the meta data have no meaning to the consumer, only meaningful to the producer of content.
Logically, different revisions of the same entry should have the same url, right?
Of course, url is not meta data…
It depends on the URL, some / many URL are disambiguation pages (leading to totally different separate pages)
I think for consistency we should treat disambiguation pages as usual pages. Then we don’t lose any data when grouping by url and pick the one with latest date_modified.
To group by URL, you need a database or the like. Back to the same place.
I already have the logic for generic tab dedupe in place so I just ran it through. Deduping by URL would be something custom made for this particular dumps. Ideally they fix it upstream.
Data cleansing can be very time consuming and tedious.
Keep in mind, URL is not unique. In other words, group by URL is not enough. It is a subtle but important issue. Several distinct URLs can point to the exact same article. It’s so frequent that it is ubiquitous. Essentially, a many(name)-to-one(article/entity)-to-many(URL) relationship. Then you throw in previous revisions into the raw json data. It is a mess.
Thank you so much for all of your elaboration!
Watch the duplicated data in this entry alone (Notice the timestamp and the redirects and categories shifting). Redirect = different URLs / Names for the SAME article content.
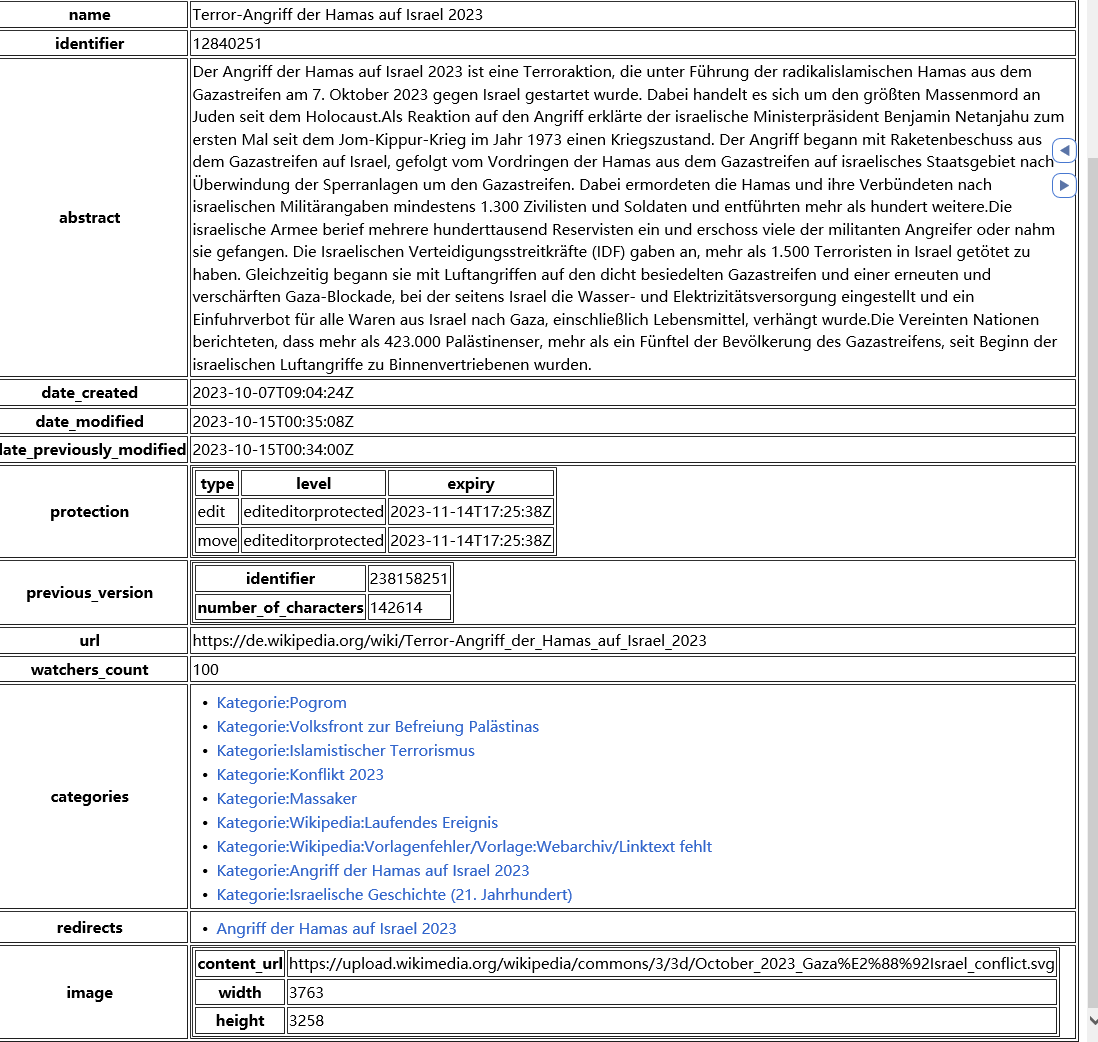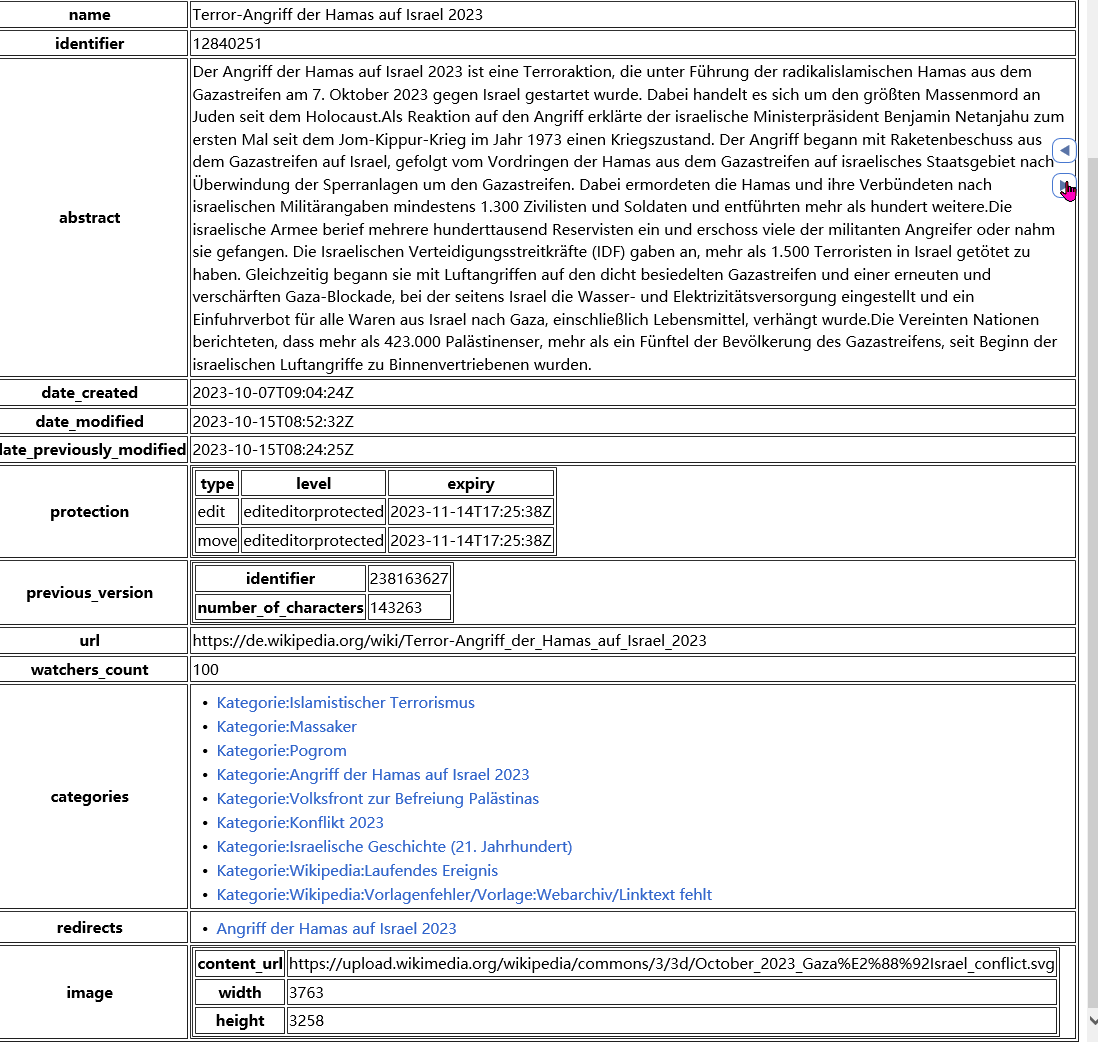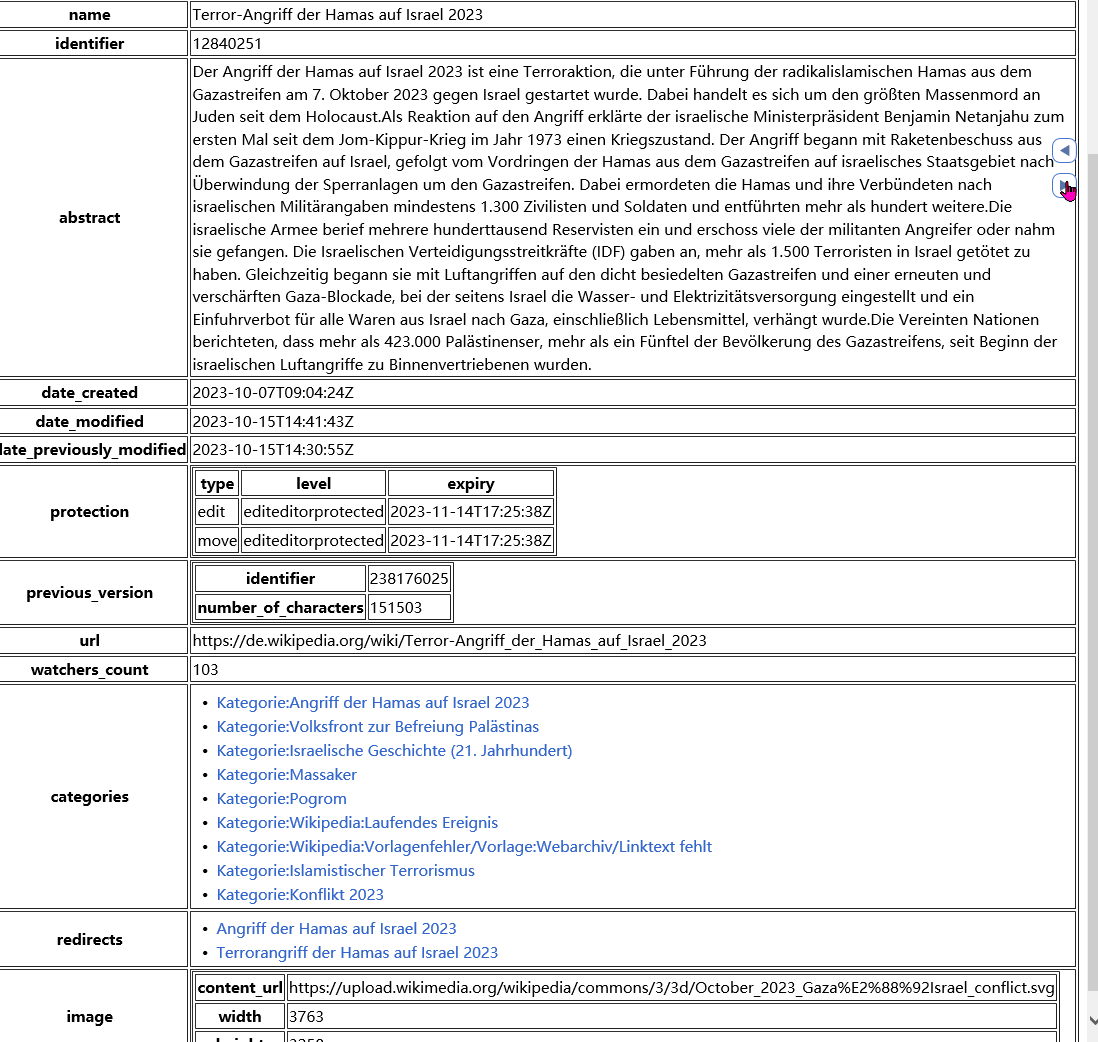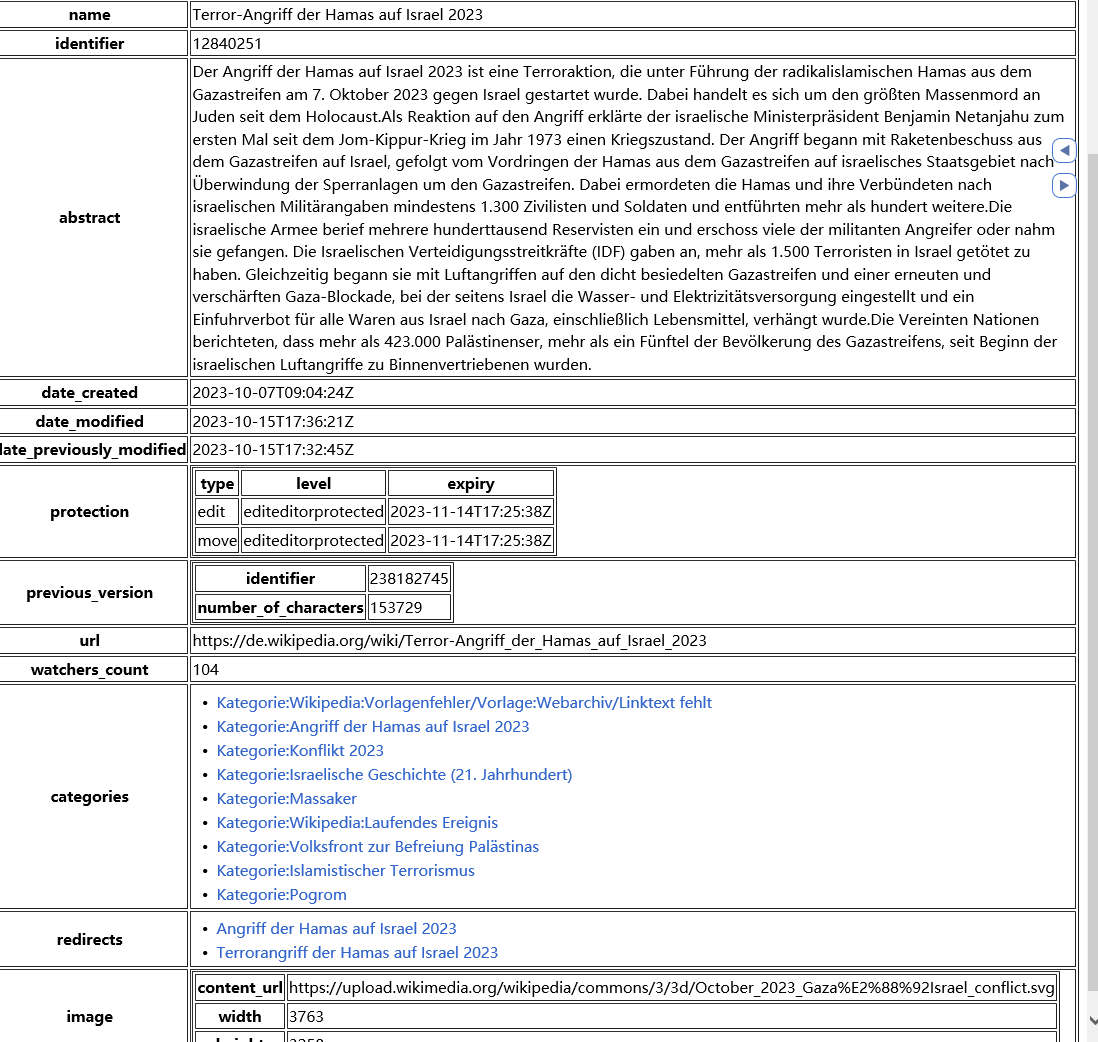
It seems from your video that the url does not change at all :v
I have found 9651 duplicate url’s in the English Wiktionary. How many dups have you found in the English Wiktionary?
Like I said, I don’t dedupe based on meta data. I only dedupe based on actual data (in units of tabs rather than the entire article). That is the only safe and sure way to dedupe. Any other method would not be complete (i.e. leaves identical copies everywhere) or safe (i.e. deletes contents which are not identical). In any case, half a million for a medium sized wikipedia is normal for this particular dumps set.
Yes, because the name = url for each mdx entry we make. This is a mdx requirement. But the duplicate contents are everywhere inside of this mdx entry as you saw in the duplicated tab names (they are kept due to tab content being slightly different from each other).
Thank you so much for your elaboration!
No problems! I gone through this mess myself ![]()
I guess the “single threaded database” you mentioned is sqlite3. I wonder why don’t you use cx_Oracle (or its new python-oracledb).
Because it came built-in with python and already ready to run without any other dependencies. It’s actually far more than enough for everything but wiki mdx.
m老师你好!
我一直在等待老师的维基系列,不知道英文,及中文维基百科哪一部是完整版,可以下载?英文版维基词典是完整版,可以下载吗?
百科都完整了(元数据都处理了)
不建议用en字典(数据太差了)
最近做了20231220的,但是找不到放在哪里了,可能上传到百度了(一楼)
这个是中文完整版吧(如是中文就OK了)?那么“EN20231020”还没有1.mdd, 2.mdd…特别想要英文版。根据您的建议英文词典就不要了。
谢谢!
