用新工具校对了一下发现原书错误真不少。
现在支持正则替换作为规则了,写了个严格验证缩略词的规则,发现不少问题

原文就有好多地方都不一致,神话好几个地方标注的〔神化〕

还有1354页第2条有22个释义,但是黑圆圈21以后没有unicode编码了,所以先用普通圆圈代替了。
现在括号匹配错误还有500多处
用新工具校对了一下发现原书错误真不少。
现在支持正则替换作为规则了,写了个严格验证缩略词的规则,发现不少问题
原文就有好多地方都不一致,神话好几个地方标注的〔神化〕
还有1354页第2条有22个释义,但是黑圆圈21以后没有unicode编码了,所以先用普通圆圈代替了。
现在括号匹配错误还有500多处
双解版、法文版的原书都有错误,比如只有一个释义项也使用❶ / -1.符号,无错不成书,文字量太大,几百万,偶尔出现这种编校失误在所难免。
目前词条对比完成:
当前双解版词条数34777
法文版词条数34779
法文版和双解版都有问题
法文版缺以下词条
中文版缺以下词条
vacillement
vaciller
vacuité
vacuole
此外法文版和中文版这两个词条fourrager和mien都有两个释义,但是没有加编号区分。
中文版词典自身遗漏缺失词条,我在以前就发现了,贴在 github 的issue里, 我想可以先把它在双解版里补上,对应的中文翻译后面手工添加。 词典原书错误举例 · Issue #6 · mahavivo/larousse · GitHub
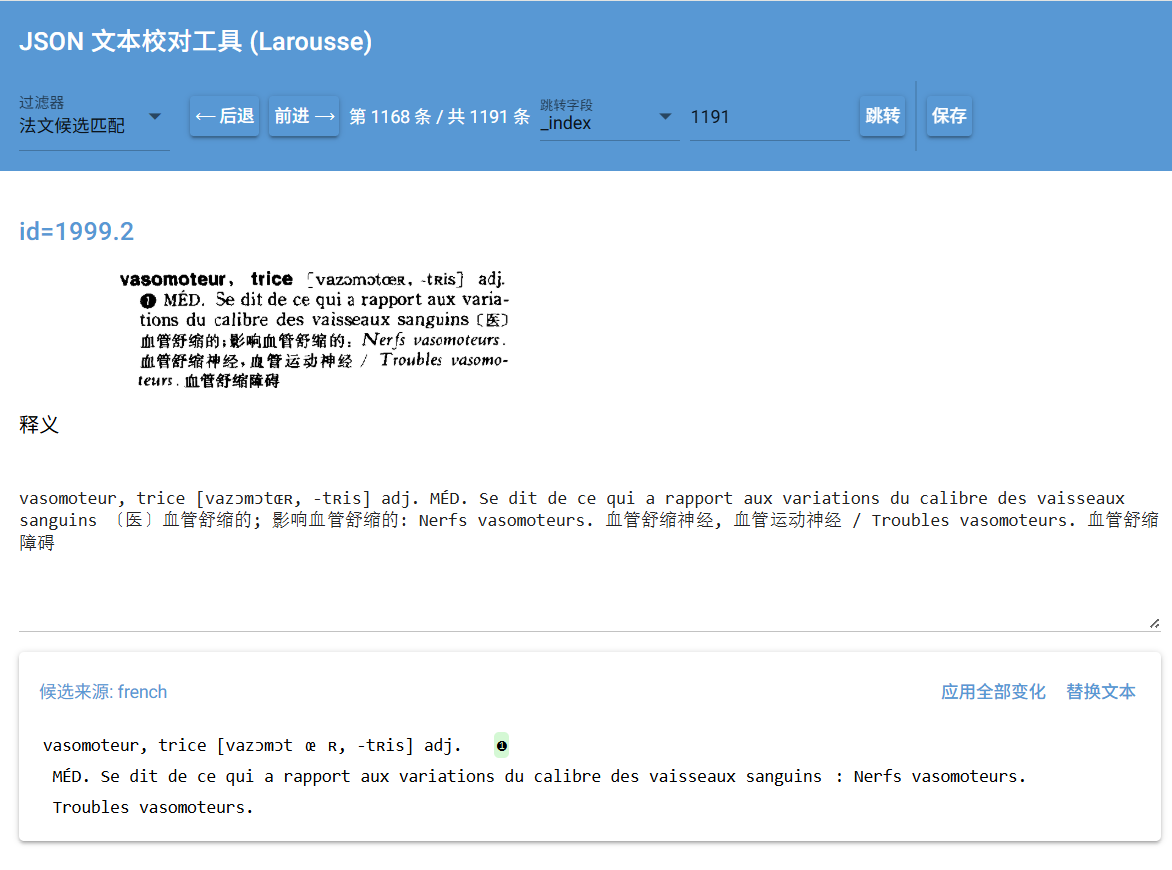
校对工具大更新,支持候选文本用不同的key查找,支持过滤字符比较,可以对比中文和法文,应用变化和替换文本分开。上方可以自定义各种字段跳转(比如拉鲁斯可以跳转到指定页page,指定页指定条目id,指定条目_index和指定单词headword。
相应的切图图片在github上吗?
图片是运行时切的,只保留了位置信息在data/image_pos.json,需要把pdf文件放到data目录才能用,pdf我一会传一下
pdf文件下载地址:
拉鲁斯法汉双解词典.pdf
链接: https://pan.baidu.com/s/1Ep0g5pFspXZJC0I0IUekgQ?pwd=3xwm 提取码: 3xwm
建议单独开一贴,供大家关注和讨论
不然就淹没在回帖中了
这个工具还没有通用化,有很多功能没实现,等实现差不多了我再单独开个帖吧。
初步通过与法文版文本程序对比的办法校核了本词典的法文部分文字,错误相对比较少,很多是变音符号丢失的问题。
至此,词典的中法文文字都对比校对过一遍,少不了漏网之鱼,但错误率应该相当低了。
在文本比对的过程中,发现了不少中法文词典本身的错误,一般会顺手纠正,不过如果问题棘手,难以一时考定,则照录双解版纸本书,以之为准。
主要的大山已经翻过了,剩下的毛病主要集中在音标和中法文的标点符号上,应该比较容易处理。
用Gemini从法文图像版里第二次单独提取了一遍音标数据,质量似乎稍微强了一些。用的prompt如下:
请OCR识别pdf文件,从中提取这个法文词典当中的词头(headword)和它的音标,其他数据不需要,全部删除抛弃。
音标数据在黑体字词头后的方括号"[]"内,且在v.t. 、n.m.、adj.这些词性标记之前。
识别时须特别留意音标的正确表示。本词典使用了如下所列的音标符号,不可使用这个列表以外的其他字符,否则就是错误;原书图像不清晰,音标中看似ā的符号,实际应该是ɑ̃。
音标符号列表:
consonnes 辅音([p][t][k][b][d][g][f][v][s][z][ʃ][ʒ][l][ʀ][m][n][ɲ][x][ŋ]);voyelles orales 口腔元音([i][e][ɛ][a][ɑ][ɔ][o][u][y][œ][ø][ə]);voyelles nasales 鼻腔元音([ɛ̃][œ̃][ɑ̃][ɔ̃]);semi-voyelles ou semi-consonnes 半元音或半辅音([j][ɥ][w])
提取的文件形式当如下,按照词典阅读顺序先后排列:
drôlement [dʀolmɑ̃]
dromadaire [dʀɔmadɛʀ]
druide [dʀɥid]
du [dy]
1. dû [dy]
2. dû, due [dy]
remaillage [ʀəmajaʒ] ou remmaillage [ʀɑ̃majaʒ]
每一个pdf文件有25页,需要全部识别,不要没完成任务就半途中断。
法文版音标第二次提取.txt (857.3 KB)
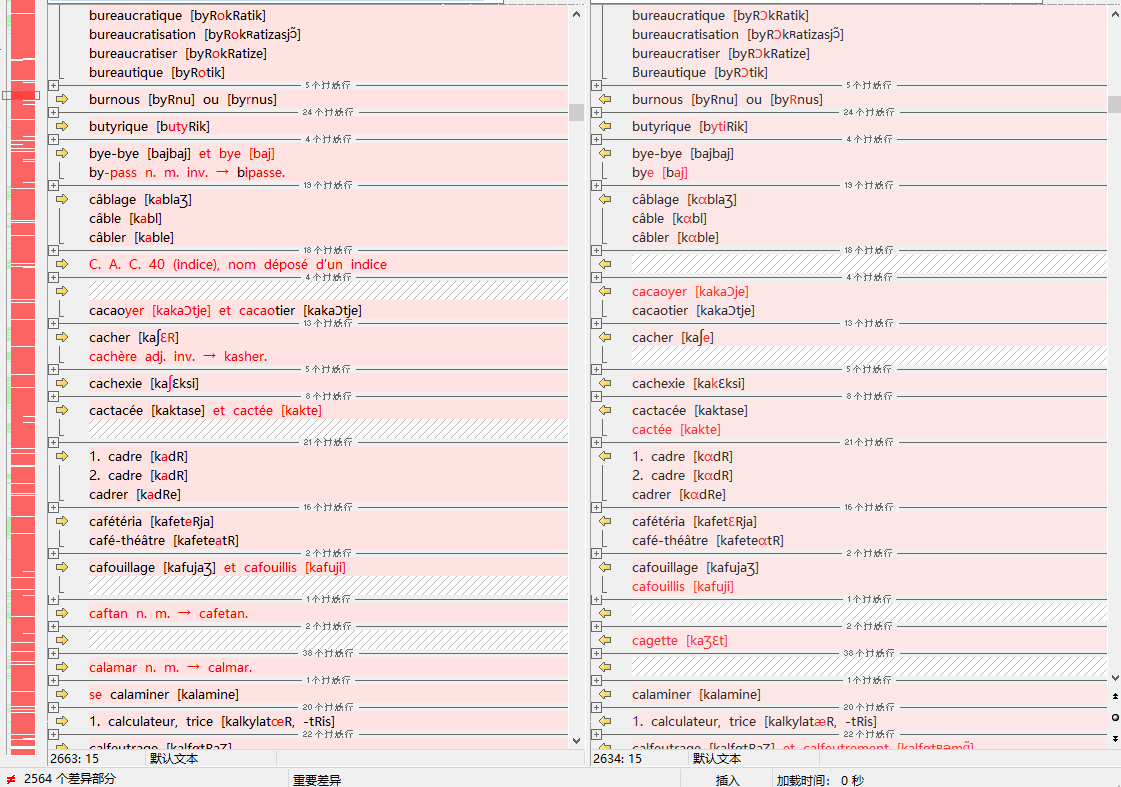
上面提取的音标文件和正在编辑的json文件差异过大,艰于直接比较利用。于是我再次从json文件里提取相关音标文字,用它们在beyond compare进行了比较,目前有2500个左右的差异。这些差异并不是说正在编校的json文件必然是错的,而是表明其可能有讹误,需要查核原始图像进一步确认。
我把比较结果的报告贴在这里:
音标比较差异报告(beyond compare).zip (94.6 KB)
感觉这两个版本都有不少错误,我还发现之前有ʃ识别成积分符号∫的,还有个别字母识别成西里尔字母的,这种直接看很难看出来。
我稍微调查了一下,目前网上应该不存在可靠的法文单词音标数据,就连拉鲁斯自己的官方网站,音标都错漏百出,最终只能回到1995年版的法文词典pdf上。人工一个个单词校对,我个人是不可能去做了,退而求其次想各种办法降低错误率。
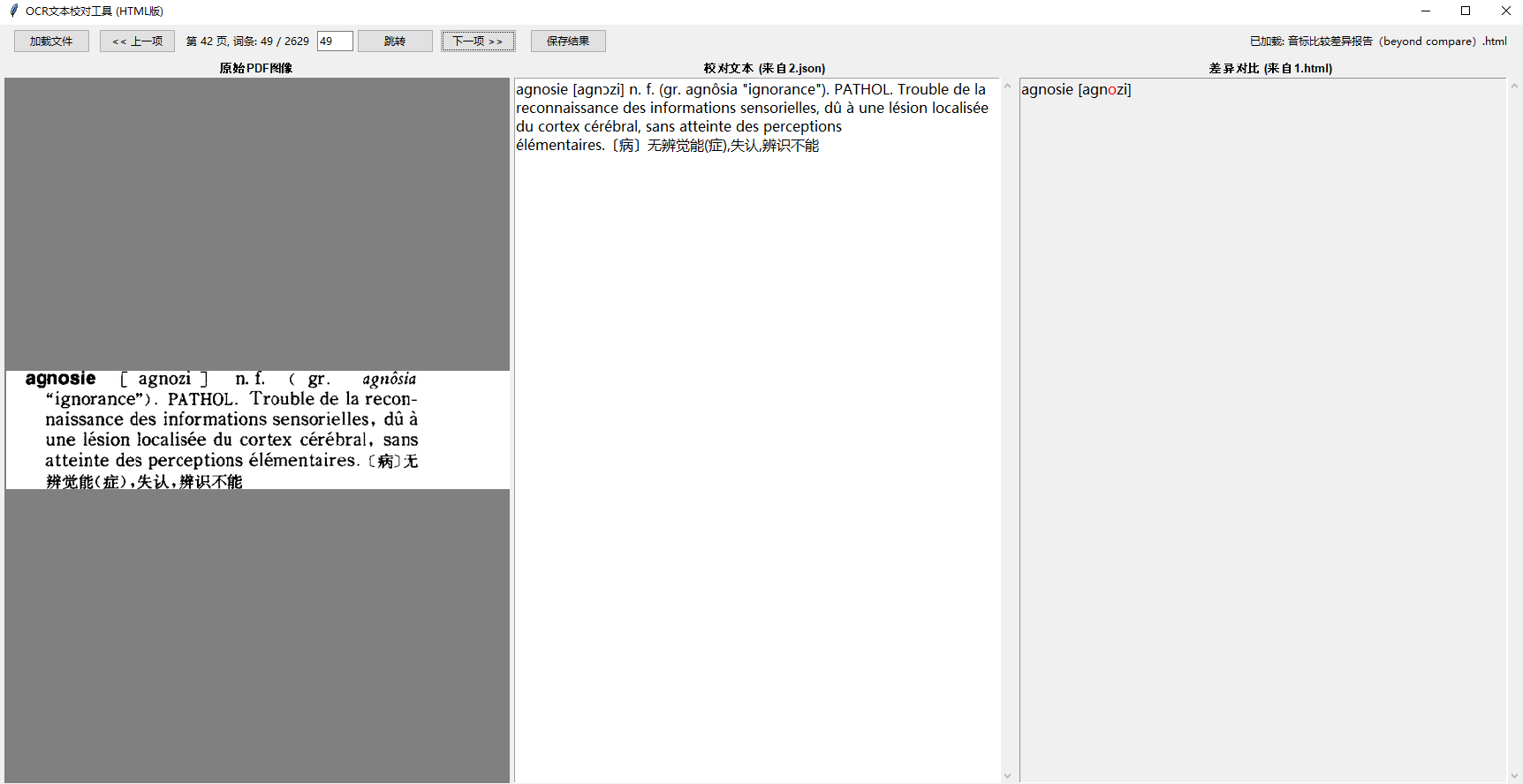
比较json、html差异报告和图像pdf,去改2500个单词的音标,工作量也不小。我打算vibe coding再写一个专门的程序,把有差异的单词、差异报告,和该单词的图像同步放在一个界面,对比它们然后修改json文件,希望磨刀不误砍柴功。
我现在写的校对工具已经支持这种了,把差异的文件新建一个json,headword填词头,然后音标填text,然后建一个候选来源和一个过滤器就能比较了。
你的程序逻辑有点复杂,我感到不容易弄明白设置和使用办法,我用自己的程序改,会更顺手方便些,反正现在是vibe coding,也不在乎代码大动干戈、伤筋动骨了。
ai写这种小型一次性程序很不错,不过维护大一点的项目感觉就不太行了,各种乱改,不过我也没用过贵的模型,不知道怎么样。
我个人完全不了解法语,单纯请教一下,ipa-dict的法语音标数据也是不可靠的吗?github上似乎并没有对法语音标可靠性的有效批评。